-
 David Trattnig authoredDavid Trattnig authored
David Trattnig authoredDavid Trattnig authored
- Advanced Configuration
- Engine API for high-availability setups
- Single Deployment
- Redundant Deployment
- Managing Active Engine State
- Playlog Synchronization for High Availability deployment scenarios
- Active Sync
- Passive Sync
- Configure Federation
- Engine 1 Node
- Engine 2 Node
- Synchronization Node
- Daemonizing Engine API
- Running with Systemd
- Running with Supervisor
Advanced Configuration
Engine API for high-availability setups
AURA Engine allows single and redundant deployment modes for high availability scenarios.
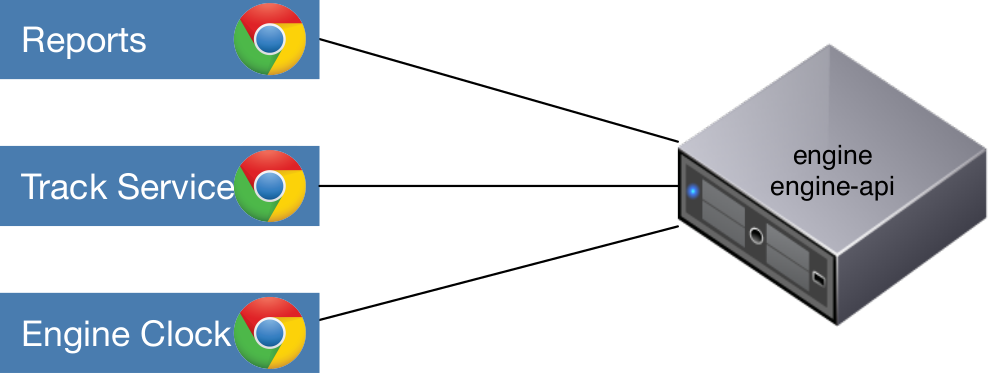
Single Deployment
Usually Engine API is deployed on the same host as the Engine.
In your live deployment you might not want to expose the API directly on the web. For security reasons it's highly recommended to guard it using something like NGINX, acting as a reverse proxy.
Redundant Deployment
In this scenario there are two Engine instances involved. Here you will need to deploy one Engine API on the host of each Engine instance. Additionally you'll have to set up a third, so-called Synchronization Node of the Engine API. This sync instance of Engine API is in charge of synchronizing playlogs and managing the active engine state.
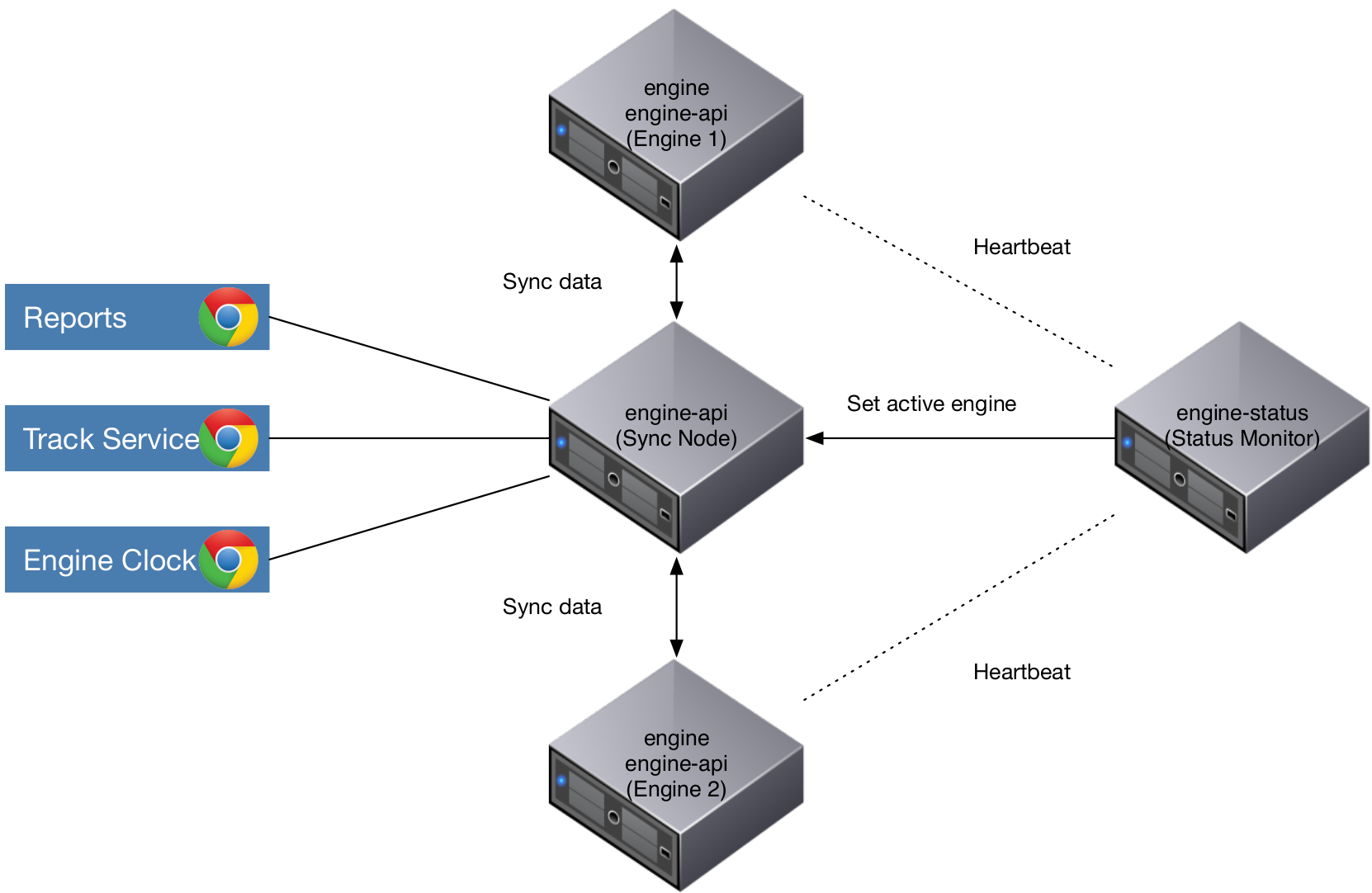
Managing Active Engine State
In order to avoid duplicate playlog storage, the Synchronization Node requires to know what the currently active Engine is. This can be achieved by some external Status Monitor component which tracks the heartbeat of both engines. In case the Status Monitor identifies one Engine as dysfunctional, it sends a REST request to the Sync Node, informing it about the second, functional Engine instance being activated.
The history of active Engine instances is stored in the database of the Sync Node. It is not only used for playlog syncing, but is also handy as an audit log.
At the moment AURA doesn't provide its own Status Monitor solution. You'll need to integrate your self knitted component which tracks the heartbeat of the engines and posts the active engine state to the Sync Node.
Playlog Synchronization for High Availability deployment scenarios
Usually when some new audio source starts playing, AURA Engine logs it to its local Engine API instance via some REST call. Now, the Local API server stores this information in its local database. Next, it also performs a POST request to the Synchronization API Server. This Sync Node checks if this request is coming from the currently active engine instance. If yes, it stores this information in its playlog database. This keeps the playlogs of individual (currently active) Engine instances in sync with the Engine API synchronization node. The Engine API synchronization node always only stores the valid (i.e. actually played) playlog records.
Active Sync
This top-down synchronization process of posting any incoming playlogs at the Engine Node also to the Synchronization Node can be called Active Sync. This Active Sync doesn't work in every scenario, as there might be the case, that the Synchronization Node is not available e.g. due to network outage, maintenance etc. In this situation the playlog obviously can not be synced. That means the local playlog at the Engine Node is marked as "not synced".
Passive Sync
Such marked entries are focus of the secondary synchronization approach, the so called Passive Sync: Whenever the Synchronization Node is up- and running again, some automated job on this node is continuously checking for records on remote nodes marked as "unsynced". If there are such records found, this indicates that there has been an outage of the Sync Node. Hence those "unsynced" records are pending to be synced. Now an automated job on the Sync Node reads those records as batches from that Engine Node and stores them in its local database. It also keeps track when the last sync has happened, avoiding to query unnecceary records on any remote nodes.
In order to avoid that this Passive Sync job might be causing high traffic on an engine instance, these batches are read with some configured delay time (see sync_interval and
sync_step_sleep in the Sync Node configuration; all values are in seconds) and a configurable batch size (sync_batch_size; count of max unsynced playlogs which are read at once).
Configure Federation
Then configure the type of federation. Depending on how you want to run your Engine API node and where it is deployed, you'll needed to uncomment one of these federation sections.
When you'll want to test federation you can use the configurations located in test/config.
Engine 1 Node
Use this section if you are running Engine standalone or if this is the first API node in a redundant deployment.
Replace api.sync.local with the actual host name or IP of your sync node.
# NODE 1
host_id=1
sync_host="http://api.sync.local:8008"Engine 2 Node
In case this is the second API node in a redundant deployment.
Replace api.sync.local with the actual host name or IP of your sync node.
# NODE 2
host_id=2
sync_host="http://api.sync.local:8008"Synchronization Node
This is the synchronization instance in a redundant setup. This instance combines all valid information coming from Engine API 1 and 2.
Replace engine1.local and engine2.local with the actual details of your main nodes.
# NODE SYNC
host_id=0
main_host_1="http://engine1.local:8008"
main_host_2="http://engine2.local:8008"
# The Engine which is seen as "active" as long no other information is received from the status monitor
default_source=1
# How often the Engine 1 and 2 nodes should be checked for unsynced records (in seconds)
sync_interval=3600
# How many unsynced records should be retrieved at once (in seconds)
sync_batch_size=100
# How long to wait until the next batch is requested (in seconds)
sync_step_sleep=2Daemonizing Engine API
Engine can also be deployed using Systemd or Supervisor.
Running with Systemd
The Systemd unit file configuration expects to be running under the user engineuser. To create such user type:
sudo adduser engineuser
sudo adduser engineuser sudoCopy the systemd unit file in config/sample/systemd to /etc/systemd/system. This configuration file is expecting you to have
Engine API installed under /opt/aura/engine-api and engineuser owning the files.
Let's start the service as root
systemctl start aura-engine-apiAnd check if it has started successfully
systemctl status aura-engine-apiIf you experience issues and need more information, check the syslog while starting the service
tail -f /var/log/syslogYou can stop or restart the service with one of these
systemctl stop aura-engine-api
systemctl restart aura-engine-apiNote, any requirements from the Installation step need to be available for that user.
Running with Supervisor
Alternatively to Systemd you can start Engine API using Supervisor. In config/sample/supervisor/aura-engine-api.conf you
can find an example Supervisor configuration file. Follow the initial steps of the Systemd setup.